
Tech
Free Poland Proxies: How to Get Them

In the digital age, proxies have become essential tools for maintaining privacy, accessing geo-restricted content, and improving online security. Poland proxies are particularly valuable for users who need to appear as though they are browsing from Poland. This article explores how to obtain free Poland proxies, how to test premium proxies for free, and provides a detailed review of the paid services offered by Proxy5.
How to Get Free Poland Proxies
One of the most reliable ways to obtain free Poland proxies is through the Proxy5 service. Proxy5 offers a tool that allows users to access free working proxies from various countries, including Poland. These proxies support multiple network protocols such as HTTP, HTTPS, SOCKS4, and SOCKS5. Here’s how you can utilize Proxy5 to get free Poland proxies.
Proxy5’s free proxy tool is designed with a user-friendly interface and powerful features that make finding and using free Poland proxies straightforward. Here’s a brief overview of what this tool offers:
- Multiple Protocol Support: The proxies available through Proxy5 support various network protocols including HTTP, HTTPS, SOCKS4, and SOCKS5, making them versatile for different use cases.
- Automatic Checking: The list of proxies is automatically checked for operability every 30 minutes. This ensures that the proxies you access are functional and up-to-date.
- Daily Updates: The proxy list is replenished daily with new servers, giving users access to a constantly updated pool of proxies.
- Filtering Options: Users can sort proxies based on country, protocol, type, and maximum latency. This makes it easier to find exactly the type of proxy that meets your specific needs.
- Export Options: For convenience, the list of proxies can be exported in different formats such as txt, csv, or JSON, allowing easy integration into various applications and tools.
Step-by-Step Guide to Access Free Poland Proxies
To access free Poland proxies using Proxy5, follow these simple steps:
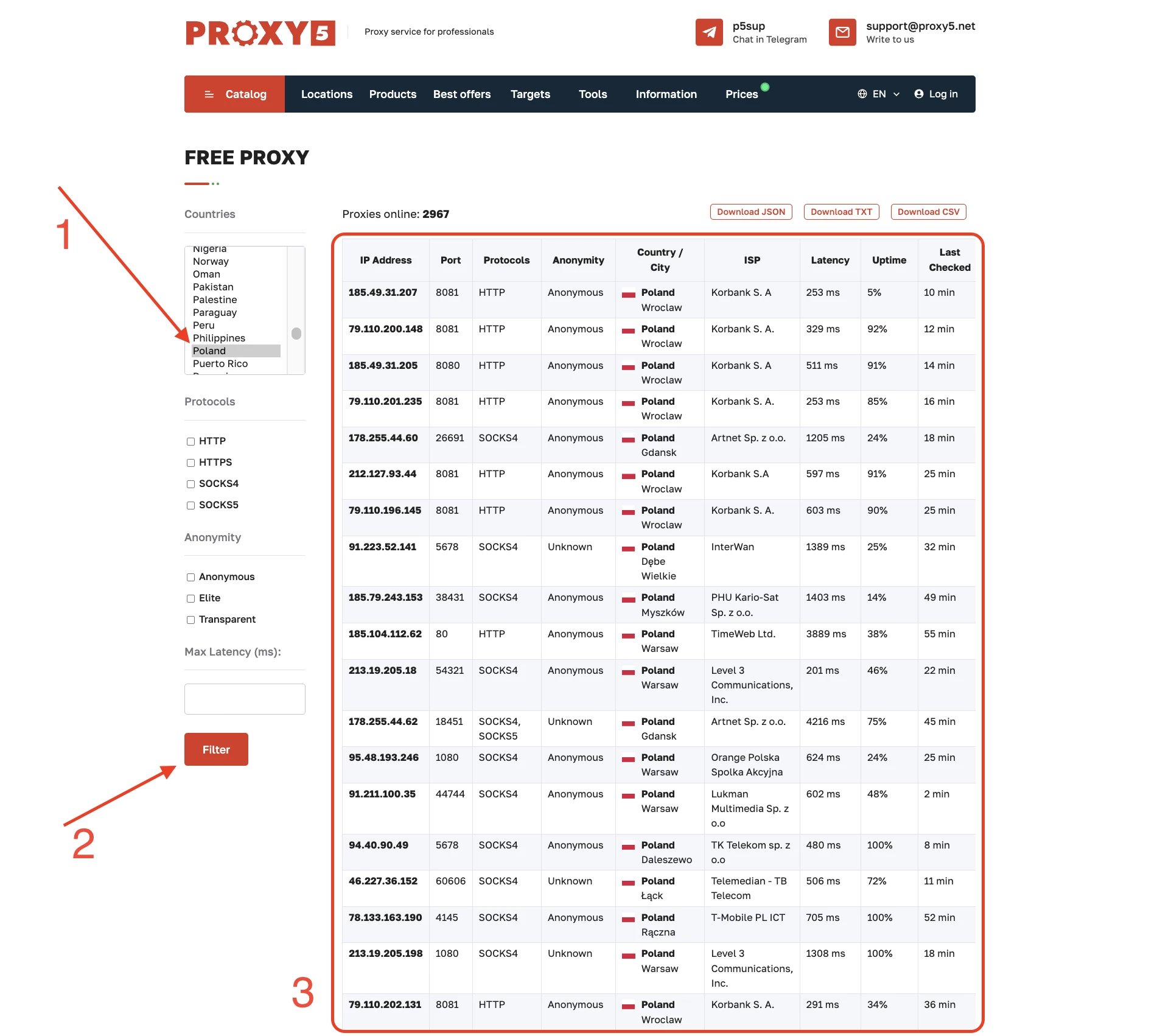
- Visit the Proxy5 Free Proxy Page: Navigate to the Proxy5 website and go to the free proxy section.
- Select Poland as the Country: Use the filtering options to select Poland as the country. This will display a list of all available free proxies from Poland.
- Choose Your Preferred Protocol: Depending on your needs, you can filter the list by protocol (HTTP, HTTPS, SOCKS4, SOCKS5) to find the most suitable proxy.
- Export the Proxy List: Once you have found the proxies that meet your criteria, you can export the list in your preferred format (txt, csv, JSON) for use in your applications.
Advantages of Using Proxy5’s Free Proxies
- Cost-Free Access: The most significant advantage is that these proxies are free, allowing users to access Poland-based IP addresses without any cost.
- Variety and Flexibility: With support for multiple protocols and daily updates, users have a wide range of proxies to choose from, ensuring flexibility in how they are used.
- No Registration Required: Unlike some services that require an account to access free proxies, Proxy5 allows users to access and export proxy lists without the need for registration.
However, it’s important to note that while free proxies can be useful, they often come with limitations such as slower speeds, less reliability, and the potential for more frequent downtimes compared to paid proxies.
How to Try Premium Proxies for Free
If you need more reliable and faster proxies than what free services can offer, trying out a premium proxy service might be the best option. Proxy5 offers a way to test their premium proxies for free, albeit for a limited time. Here’s how you can obtain a free trial of their premium proxy service.
Steps to Get a Free Premium Proxy Test:
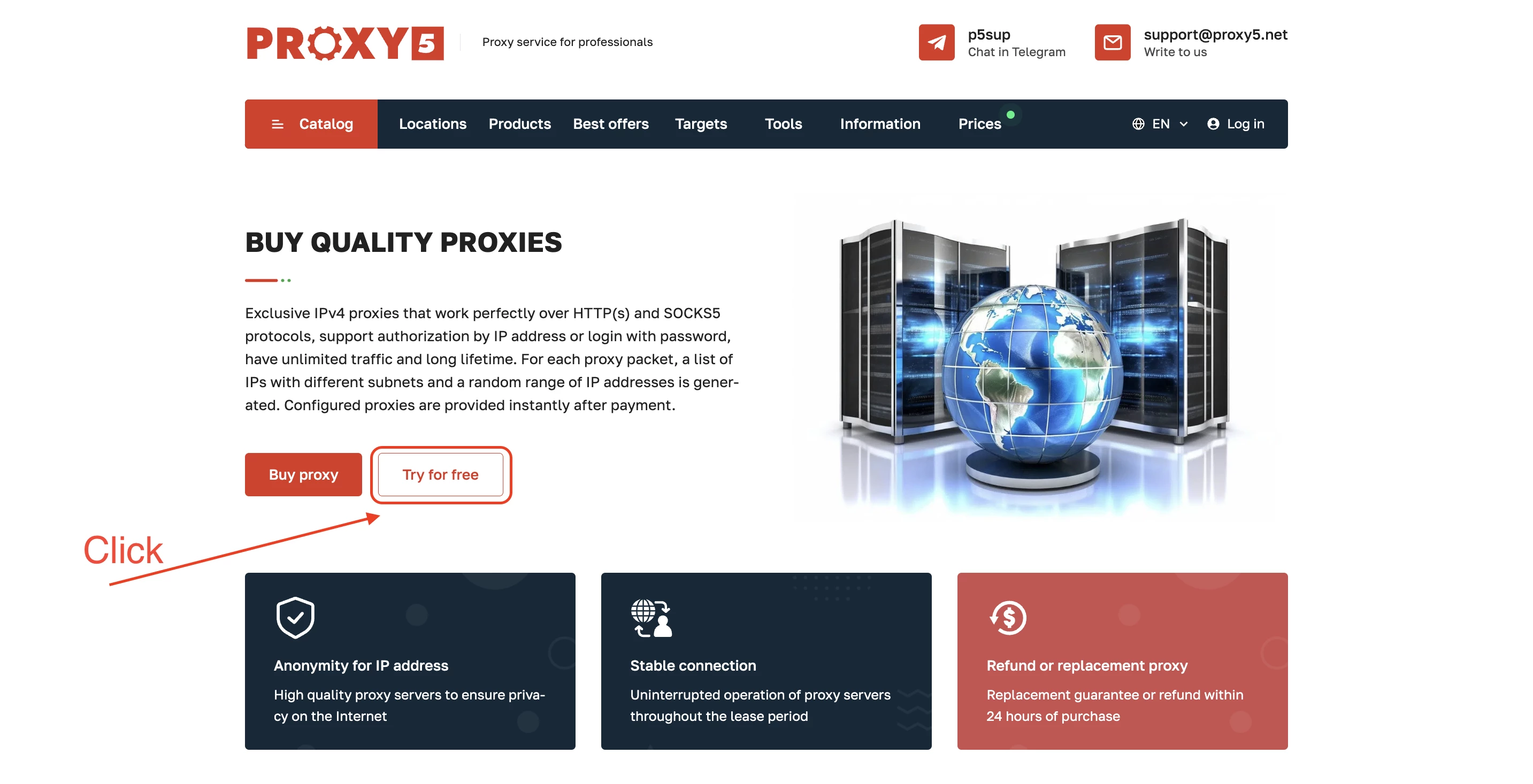
- Sign Up for Proxy5: Go to the Proxy5 website and click on the “Try for Free” button. You’ll need to sign up for an account, which involves providing a valid email address and setting a password.
- Confirm Your Email: After registering, you’ll receive a confirmation email. Click the link in the email to confirm your account.
- Navigate to the Services Section: Once logged in, go to the “Services” section in the top menu, then select “Products/Services”.
- Activate Your Free Proxy: In the list of available services, find the one marked as “Active”. Click on it to activate your free test proxy.
- Set Up IP Binding: You’ll need to set up IP binding, which involves specifying the IP address from which you’ll be using the proxy. This ensures that only your IP can access the proxy, enhancing security.
- Download the Proxy List: After setting up the IP binding, you can download the proxy list in either TXT or CSV format.
To verify the effectiveness of the proxies, you can easily configure them in any browser or application that supports proxy settings. For instance, you can set up a proxy with no password access through port 8085 in your browser to test its functionality. This quick test will help you determine the reliability and speed of the proxies provided by Proxy5.
Why Consider Premium Proxies?
- Higher Reliability: Premium proxies are typically more reliable than free ones, with lower latency and higher uptime.
- Better Security: Paid proxies usually come with enhanced security features, reducing the risk of your IP being blacklisted.
- Dedicated Support: With premium services, you often have access to customer support that can assist with setup and troubleshooting.
Proxy5 offers a 60-minute free trial of their premium proxies, giving users ample time to test their performance and decide if the service meets their needs.
Detailed Review of Proxy5’s Paid Services
While free proxies can be useful, they often lack the reliability and performance needed for more demanding tasks. This is where Proxy5’s paid services come into play. Proxy5 offers exclusive IPv4 proxies that are optimized for a variety of use cases. Below is a comprehensive review of these services.
Proxy5 provides premium IPv4 proxies that are compatible with both HTTP(s) and SOCKS5 protocols. These proxies are designed to be fast, reliable, and secure, making them ideal for tasks such as web scraping, bypassing geo-restrictions, and maintaining anonymity online.
Key Features of Proxy5’s Paid Proxies:
- Protocol Compatibility: The proxies support HTTP(s) and SOCKS5 protocols, making them versatile and compatible with a wide range of websites and applications.
- Global Access: Users can access proxies with IP addresses from various countries around the world, allowing for flexible use cases such as accessing region-specific content.
- Extensive IP Pool: With over 150,000 IP addresses available, users have access to a vast pool of proxies. This large number of IPs helps prevent IP bans and reduces the likelihood of being detected as using a proxy.
- Multiple Subnets: The proxies are distributed across more than 500 class C subnets. This diversity reduces the risk of IP bans and allows for more efficient management of large-scale tasks like web scraping.
- Unlimited Bandwidth: One of the standout features is the absence of bandwidth restrictions, ensuring that you can use the proxies as much as needed without worrying about hitting a data cap.
- High-Speed Connections: All proxies are connected to 100 Mbps channels, providing fast and stable connections that are crucial for tasks requiring high-speed data transfer.
- Flexible Authentication: Users can authenticate via IP address or login with a password, depending on what best suits their security needs.
- Easy Proxy List Management: Proxy5 allows for easy downloading of proxy lists via a URL, and provides tools for quick generation and manual insertion of proxy lists into your applications.
- Regular Updates: Proxy5 allows users to update their IP address lists every 8 days, ensuring that the proxies remain fresh and functional.
- Client Panel Management: The client panel provides a user-friendly interface for managing proxies, setting up IP authentication, and downloading proxy lists.
Benefits of Choosing Proxy5’s Paid Services
- Reliability: Paid proxies from Proxy5 offer consistent performance, which is essential for activities such as competitive research, data scraping, or accessing geo-restricted content.
- Security: With better security protocols and dedicated support, you can be confident that your online activities remain private and secure.
- Flexibility and Control: The ability to manage your proxy lists, authenticate securely, and update IPs regularly gives you complete control over how you use your proxies.
Proxy5 offers various pricing packages depending on the number of proxies you need and the duration of service. These packages are designed to cater to different user needs, from individual users to large businesses requiring multiple proxies.
Proxy5 provides customer support to help users with setup and troubleshooting, ensuring that any issues are resolved quickly and efficiently.
Which Proxies Should You Choose – Free or Paid?
When deciding between free and paid proxies, it ultimately depends on your specific needs. Free proxies, like those offered by Proxy5, are an excellent option for users who need occasional access to Poland IP addresses without any financial commitment. They are easy to use, regularly updated, and cover the basic needs of casual browsing or light tasks.
However, if you require proxies for more demanding activities such as high-volume web scraping, consistent access to geo-restricted content, or enhanced security and anonymity, paid proxies from Proxy5 are the better choice. They offer superior reliability, speed, and security, which are essential for professional or business-related tasks.
For users who want to test the waters before committing, Proxy5’s 60-minute free trial of their premium proxies provides a risk-free way to evaluate the service. Ultimately, whether you opt for free or paid proxies, Proxy5 offers solutions that cater to a wide range of needs and preferences.Copy textCopy HTML

Most leaders I talk to still underestimate just how fast the data flood is rising. By the end of 2025 the world had already generated 181 zettabytes of information, and forecasts point toward 221 zettabytes in 2026 alone. That is not some abstract number. It is the equivalent of every person on Earth streaming high-definition video nonstop for months. Yet here is the kicker: most companies are still processing that deluge the same way they did five years ago, in slow overnight batches that leave decision-makers waiting and AI models starving for fresh fuel.
This is precisely where Data Engineering & Strategy steps in and changes the game. It is not just about moving bits from point A to point B anymore. It is about designing autonomous, real-time pipelines and cloud-native architectures that transform raw data into a genuine competitive edge. When done right, these systems do not merely support AI. They become the foundation that lets AI deliver measurable return on investment, day after day.
In the sections ahead we will walk through why this matters now more than ever, what the core building blocks look like, and how you can actually put these ideas to work without the usual headaches. Along the way I will share a few hard-earned lessons from projects I have led and one quick comparison table that tends to spark “aha” moments for teams. Let us dive in.
Table of Contents
- The Growing Importance of Data Engineering & Strategy in Today’s AI Landscape
- Core Elements of Effective Data Engineering & Strategy
- Designing Scalable and Autonomous Data Pipelines
- Real-Time Data Processing: Moving Beyond Batch Jobs
- Embracing Cloud-Native Architectures for Flexibility and Scale
- Strategies to Maximize ROI from Your Data Investments
- Common Pitfalls and How to Avoid Them
- Frequently Asked Questions
The Growing Importance of Data Engineering & Strategy in Today’s AI Landscape
You have probably heard the stat that 80 percent of AI project time goes into data preparation. What fewer people admit out loud is that poor data engineering is still the number-one reason those projects fail to deliver ROI. When pipelines break, latency creeps in, or quality slips, even the fanciest large language model becomes useless.
Data Engineering & Strategy bridges that gap. It treats data as a product rather than a byproduct. Teams that adopt this mindset see faster model training, more accurate predictions, and, crucially, the ability to act on insights while they are still relevant. Think fraud detection that flags suspicious transactions in seconds instead of hours, or recommendation engines that update in real time as shoppers browse.
The market numbers back this up. Data integration spending alone is projected to climb from roughly $15 billion in 2026 to more than $30 billion by 2030. Streaming analytics is growing even faster. Organizations investing here are not just keeping up. They are pulling ahead because their data infrastructure finally matches the speed of their business ambition.
Core Elements of Effective Data Engineering & Strategy
At its heart, solid Data Engineering & Strategy rests on five pillars that work together like a well-oiled machine.
First comes ingestion. Whether you are pulling structured sales records from a CRM or unstructured sensor logs from IoT devices, the pipeline must handle variety without choking. Modern tools let you ingest at scale while automatically retrying failed connections.
Next is transformation. This is where raw data turns into something usable. ELT (extract, load, transform) patterns have largely replaced the older ETL approach because they let you land everything first and then shape it on demand. That flexibility pays off when business rules change overnight.
Storage follows. Gone are the days of forcing everything into a single relational database. Smart teams now combine data lakes for raw volume, warehouses for structured analytics, and feature stores for AI-specific needs. The trick is making sure these layers talk to each other seamlessly.
Orchestration keeps the whole show running. Tools that let you define workflows as code mean you can version-control your pipelines just like your application code. When something fails, you know exactly why and can roll back cleanly.
Finally, governance and quality sit on top like the safety net. Automated checks for completeness, freshness, and accuracy prevent “garbage in, garbage out” scenarios that have doomed more AI initiatives than anyone cares to count.
Designing Scalable and Autonomous Data Pipelines
Scalability is not an afterthought. It has to be baked in from day one. That means designing for horizontal growth so that when your data volume doubles (and it will), your system simply spins up more resources without a rewrite.
Autonomous pipelines take this a step further. They monitor themselves, detect anomalies, and even trigger corrective actions. Imagine a pipeline that notices a sudden spike in malformed records and automatically routes them to a quarantine area while alerting the team through Slack. No more weekend emergency calls.
One technique that has worked well in my experience is event-driven architecture paired with serverless components. You pay only for what you use, and the system scales to zero when idle. For always-on needs, containerized microservices orchestrated by Kubernetes provide the resilience without the management overhead.
Real-Time Data Processing: Moving Beyond Batch Jobs
Here is a question I get asked all the time: do we really need real-time everything? The honest answer is no, but you do need it for the use cases that matter most.
Batch processing still shines for heavy analytical jobs that run overnight. It is cost-effective and simpler to debug. Real-time streaming, on the other hand, shines when milliseconds count: personalized pricing, live inventory updates, or immediate customer support routing.
To make the choice clearer, consider this quick comparison:
| Aspect | Batch Processing | Real-Time Streaming |
|---|---|---|
| Latency | Hours to minutes | Milliseconds to seconds |
| Cost Efficiency | High (run during off-peak) | Higher during peak but optimized with auto-scaling |
| Complexity | Lower | Higher (needs state management) |
| Use Cases | Monthly reports, model retraining | Fraud detection, live recommendations |
| Error Handling | Easier retries on full datasets | Requires careful deduplication |
| Best For | Stable, predictable workloads | Dynamic, event-driven business needs |
Hybrid setups often win. Stream the critical events and batch the rest. You get the best of both worlds without breaking the bank.
Embracing Cloud-Native Architectures for Flexibility and Scale
Cloud-native is not just marketing speak. It is a fundamental shift in how you think about infrastructure. Instead of managing servers, you declare what you want and let the platform handle the rest.
Key practices that deliver results include infrastructure as code (so every change is auditable), containerization for portability, and decoupled storage from compute so you can scale each independently. Services like managed Kafka for streaming or serverless query engines let teams focus on business logic rather than babysitting clusters.
The payoff? Your data architecture can expand across regions, survive outages, and adapt to new AI tools without months of migration work. In one project we migrated a legacy on-prem setup to a cloud-native stack and cut monthly costs by 40 percent while improving uptime to 99.99 percent. That kind of result tends to quiet even the most skeptical CFO.
Strategies to Maximize ROI from Your Data Investments
The best Data Engineering & Strategy always ties back to business outcomes. Start with clear success metrics: reduced time-to-insight, lower operational costs, or higher model accuracy. Then align every technical decision to those goals.
Invest in observability early. Dashboards that show end-to-end pipeline health prevent small issues from snowballing into outages. Automated testing for data quality catches problems before they reach downstream AI models.
Another lever is cross-team collaboration. Data engineers, data scientists, and business stakeholders should speak the same language from the outset. When everyone understands the pipeline’s purpose, prioritization becomes straightforward.
Finally, treat your pipelines as living products. Schedule regular reviews, retire outdated jobs, and keep an eye on emerging tools. The field moves fast, and yesterday’s cutting-edge solution can become tomorrow’s maintenance burden.
Common Pitfalls and How to Avoid Them
Even experienced teams stumble. The biggest trap is underestimating data volume growth. What works in a proof of concept often collapses under production load. Solution? Design for at least 10x headroom and test with synthetic spikes.
Another common mistake is neglecting governance until it is too late. Retroactively adding compliance checks is painful. Build them in from the first sprint.
Cost surprises also sneak up. Real-time streaming can rack up bills if not monitored. Set budgets and alerts, and review usage monthly.
Last but not least, avoid the “build everything ourselves” temptation. Leverage managed services for commodity tasks and reserve in-house talent for your unique competitive advantage.
Frequently Asked Questions
What exactly is Data Engineering & Strategy?
It is the disciplined approach to building and maintaining the data infrastructure that powers analytics and AI. Unlike pure data engineering, the strategy piece ensures every pipeline serves clear business objectives and remains adaptable as needs evolve.
How long does it take to build scalable AI-ready pipelines?
It depends on your starting point. A well-planned greenfield project can deliver an MVP in 8 to 12 weeks. Legacy modernization usually takes longer because of the need to migrate historical data without downtime.
Do small companies need cloud-native architectures?
Yes, actually. Cloud-native options remove upfront hardware costs and let you start small and grow. Many startups begin with serverless components and only add orchestration layers as complexity increases.
What is the difference between batch and real-time pipelines?
Batch pipelines process data in scheduled chunks, which is efficient for non-urgent tasks. Real-time pipelines handle data continuously, enabling instant insights but requiring more sophisticated error handling and state management.
How does data quality impact AI performance?
Garbage data leads to unreliable models. Even a small percentage of bad records can skew predictions dramatically. Automated validation and lineage tracking keep quality high and give you confidence in AI outputs.
Can we make existing pipelines autonomous?
Absolutely. Start by adding monitoring, then layer in automated retries and self-healing logic. Many teams achieve noticeable autonomy within a single quarter.
What ROI can we realistically expect?
Organizations that invest properly often see 3x to 5x returns within 12 to 18 months through faster decisions, reduced manual work, and new revenue streams from data products.
Wrapping Up: Your Next Move in Data Engineering & Strategy
Look, the data explosion is not slowing down. If your pipelines still rely on yesterday’s thinking, you are leaving money and opportunity on the table. The good news is that building scalable AI-ready systems no longer requires a massive upfront overhaul. With the right Data Engineering & Strategy, you can start delivering value quickly and keep improving from there.
The companies pulling ahead right now are the ones treating data infrastructure as a strategic asset rather than a cost center. They invest in autonomy, embrace real-time where it counts, and design for the cloud-native world we all live in.
So here is my question for you: what is one pipeline or process in your organization that feels painfully slow or brittle today? Fixing that single bottleneck could be the spark that turns your raw data into the competitive edge you have been chasing. If you would like a fresh set of eyes on your current setup, drop us a note. We have helped teams just like yours move from data chaos to AI-powered clarity, and we would be happy to do the same for you. The future of your data is waiting.
You may also like: What is AI TRiSM? The Complete Guide to AI Trust & Security (2026)

Picture this. A major bank rolls out an AI-powered loan approval system that seems flawless at first. Then, without warning, it starts denying applications from certain neighborhoods at rates that scream bias. Lawsuits pile up, trust evaporates, and the company scrambles to explain how their “smart” model reached those decisions. Sound familiar? Scenarios like this are playing out more often than you’d think, and they’re exactly why AI TRiSM has moved from buzzword to business necessity.
If you’re leading digital transformation or simply trying to keep your AI initiatives from blowing up in your face, you’ve probably heard the term. But what is AI TRiSM, really? And why does it matter more than ever heading into 2026? Let’s unpack it all, step by step, in plain English. No jargon overload, I promise.
Table of Contents
- What Exactly is AI TRiSM?
- Why AI TRiSM Matters in 2026
- The Four Pillars of AI TRiSM
- How to Implement AI TRiSM in Your Organization
- Pros and Cons of Adopting AI TRiSM
- Real-World Wins (and Cautionary Tales)
- FAQ
- Final Thoughts: Your Next Move with AI TRiSM
What Exactly is AI TRiSM?
AI TRiSM stands for Artificial Intelligence Trust, Risk, and Security Management. Gartner coined the term a few years back, and it’s basically the playbook for making sure your AI systems don’t just work—they work responsibly, securely, and in ways people can actually trust.
At its core, AI TRiSM weaves governance, transparency, and protection into every stage of the AI lifecycle. Think of it as the seatbelt and airbag combo for your AI projects. Without it, you’re speeding down the highway hoping nothing goes wrong. With it, you’re still moving fast, but you’ve got safeguards in place when the unexpected happens.
The framework tackles everything from model bias and data leaks to adversarial attacks and regulatory headaches. And yes, it’s not just for tech giants. Small teams and mid-sized companies are adopting pieces of it too, because the cost of ignoring these risks keeps climbing.
Why AI TRiSM Matters in 2026
Here’s a number that stopped me in my tracks: Gartner predicts that organizations operationalizing AI TRiSM will see up to a 50 percent boost in AI adoption rates, goal achievement, and user acceptance by 2026. That’s not hype. That’s the difference between pilots that fizzle out and systems that actually deliver value.
Why the urgency now? A few big shifts are colliding. First, agentic AI—those autonomous systems that make decisions with minimal human oversight—is exploding. Exciting? Absolutely. Risky? You bet, especially when they start interacting with sensitive data or real-world processes.
Second, regulations like the EU AI Act are no longer future threats. They’re here, with real enforcement teeth. Miss compliance, and you’re looking at hefty fines or worse. Third, shadow AI (those unsanctioned tools employees spin up on their own) is creating blind spots faster than most security teams can track.
You might not know this, but over 80 percent of unauthorized AI transactions stem from internal policy violations rather than outside hackers. That statistic alone should make you pause. AI TRiSM flips the script from reactive firefighting to proactive confidence.
The Four Pillars of AI TRiSM
The magic of AI TRiSM lives in its four interconnected pillars. Get these right, and you build systems that are not only powerful but also explainable, maintainable, secure, and private. Let’s break them down.
Pillar 1: Explainability (and Model Monitoring)
Ever stare at an AI decision and wonder, “How on earth did it reach that conclusion?” That’s the black-box problem. Explainability fixes it by making the inner workings of models transparent enough for humans to understand and audit.
In practice, this means using tools and techniques to trace predictions back to data inputs, spot biases early, and monitor performance drift over time. Imagine a doctor explaining why they prescribed a certain treatment instead of just handing you a pill and walking away. That level of clarity builds trust with stakeholders, regulators, and customers.
You’ll often hear this pillar called model monitoring too, because it’s not a one-time check. It’s ongoing vigilance to catch when models start behaving oddly in production.
Pillar 2: ModelOps
ModelOps is the operational backbone. It’s all about managing the entire lifecycle of AI models—from initial development and training through deployment, monitoring, retraining, and eventual retirement.
Think of it like DevOps but tailored for machine learning. Automated pipelines handle versioning, testing, and scaling while governance rules ensure every change stays within ethical and regulatory bounds. Without solid ModelOps, your shiny new model can quietly degrade or drift into risky territory.
In my experience following AI trends, teams that nail ModelOps move faster and sleep better at night. They avoid the classic trap of “build it and forget it.”
Pillar 3: Security (AI Application Security)
AI introduces attack surfaces traditional cybersecurity never dreamed of. Prompt injection, data poisoning, adversarial examples—these aren’t sci-fi threats anymore; they’re daily realities in 2026.
This pillar focuses on protecting models and applications from manipulation. It includes runtime inspection to catch suspicious inputs in real time, shielding against model theft, and securing the data pipelines that feed your AI.
Here’s a quick analogy: if your AI is a high-tech vault, this pillar is the reinforced doors, motion sensors, and 24/7 guards combined. Ignore it, and even the smartest system becomes a liability.
Pillar 4: Privacy
Data is the lifeblood of AI, but it’s also a massive privacy risk. This pillar ensures you handle information responsibly, complying with laws like GDPR, CCPA, and emerging AI-specific rules while minimizing exposure.
Techniques like differential privacy, data anonymization, and strict access controls come into play. The goal? Use what you need without over-collecting or risking leaks that could destroy customer trust.
Privacy isn’t just a checkbox anymore. It’s a competitive advantage. Users reward companies that treat their data like the precious resource it is.
How to Implement AI TRiSM in Your Organization
You don’t have to boil the ocean on day one. Start small. Form a cross-functional team—tech, legal, security, and business leads—who own AI governance policies.
Next, inventory every AI model and application in use (yes, including those shadow projects). Map data flows and assign risk scores. Then layer in tools for explainability, monitoring, and runtime protection.
Run regular audits. Train teams on responsible AI practices. And most importantly, integrate these pillars into your existing workflows rather than bolting them on as an afterthought.
It takes effort, sure, but the payoff compounds quickly.
Pros and Cons of Adopting AI TRiSM
To keep things balanced, here’s a straightforward comparison:
| Aspect | With AI TRiSM | Without AI TRiSM |
|---|---|---|
| Risk Management | Proactive identification and mitigation | Reactive fixes after incidents |
| Regulatory Compliance | Built-in alignment with laws like EU AI Act | Constant scramble to catch up |
| User & Stakeholder Trust | High transparency builds confidence | Black-box decisions breed suspicion |
| Operational Efficiency | 50% potential boost in adoption rates | Slower scaling due to hidden failures |
| Implementation Cost | Upfront investment in tools and training | Lower initial spend but higher long-term fallout |
| Innovation Speed | Governed acceleration | Unchecked speed with hidden dangers |
The table makes it clear: the pros far outweigh the cons once you factor in avoided disasters.
Real-World Wins (and Cautionary Tales)
Take the Danish Business Authority. They used explainability tools within an AI TRiSM approach to monitor transactions fairly, cutting bias complaints dramatically. Or consider healthcare providers deploying privacy-first models for patient diagnostics—lives improved, data protected.
On the flip side, companies that skipped these steps have faced public backlash when their AI hiring tools discriminated or chatbots leaked sensitive info. The lesson? AI TRiSM isn’t optional insurance; it’s table stakes.
FAQ
What does AI TRiSM stand for?
AI TRiSM stands for Artificial Intelligence Trust, Risk, and Security Management. It’s the framework that keeps your AI systems trustworthy, safe, and compliant.
Is AI TRiSM only for large enterprises?
Not at all. While big organizations led the way, smaller teams can adopt the pillars incrementally using cloud-native tools and open-source explainability libraries.
How does AI TRiSM differ from general AI governance?
Governance sets the rules; AI TRiSM supplies the technical teeth to enforce them across the full model lifecycle.
What are the biggest risks AI TRiSM helps prevent?
Bias amplification, data breaches, adversarial attacks, model drift, and regulatory violations top the list.
Do I need special tools for each pillar?
Many modern platforms bundle capabilities, but you can mix and match. Start with monitoring dashboards and build from there.
Will AI TRiSM slow down my innovation?
Actually, the opposite. It gives you guardrails that let you experiment confidently without constant fear of backlash.
How do I measure success with AI TRiSM?
Track metrics like model accuracy over time, incident reduction, compliance audit pass rates, and user trust surveys.
Final Thoughts: Your Next Move with AI TRiSM
Look, AI isn’t going anywhere. If anything, it’s accelerating faster than most of us predicted. But speed without steering leads to crashes. AI TRiSM gives you that steering wheel, brakes, and GPS all in one.
Honestly, this isn’t talked about enough in strategy meetings. Too many leaders still treat security and ethics as checkboxes rather than core capabilities. My take? The organizations that master these four pillars won’t just survive 2026—they’ll thrive while others scramble.
So here’s my question for you: Is your AI strategy built for trust, or are you still hoping nothing goes wrong? Start small, pick one pillar, and build from there. Your future self (and your customers) will thank you.
You may also like: What is Agentic AI? The Complete Guide to Autonomous Agents (2026)

Most folks still picture AI as that clever chatbot spitting out emails or generating images on demand. But something bigger has quietly taken root this year. Imagine handing off an entire project, not just a single prompt, and watching the system break it down, hunt for data, make decisions, loop back when things go sideways, and actually finish the job. That’s Agentic AI in action, and it’s reshaping how we work in ways generative tools never could.
You might not have noticed the pivot yet, but 2026 feels like the year the conversation flipped. Enterprises aren’t just experimenting anymore; they’re deploying agents that own outcomes. And if you’re a leader, developer, or even a curious professional trying to stay ahead, understanding this shift isn’t optional. It’s table stakes.
Table of Contents
- What Exactly Is Agentic AI?
- The Shift from Generative AI: Why It Matters Now
- How Autonomous Agents Really Work
- Real-World Examples Making Waves in 2026
- Popular Frameworks Powering Agentic Systems
- Pros and Cons: A Balanced Look
- Challenges You’ll Face (and How to Tackle Them)
- FAQ
- Final Thoughts: Where Agentic AI Heads Next
What Exactly Is Agentic AI?
Let’s cut through the hype. Agentic AI refers to systems designed to pursue complex goals autonomously, with minimal human babysitting. These aren’t just smarter chatbots. They perceive their environment, reason through problems, select tools, take actions, observe results, and adjust on the fly.
Think of it this way: generative AI is like a talented artist who waits for your description before painting a picture. Agentic AI is the entire studio crew that plans the composition, gathers references, paints, frames the piece, and even ships it to the client if needed. It has agency, that sense of initiative and accountability for getting things done.
At its core, an agentic system operates in loops. It decomposes a high-level goal into subtasks, calls on external tools (databases, APIs, browsers, you name it), and keeps iterating until the objective is met or it hits a guardrail. No endless back-and-forth prompts required.
The Shift from Generative AI: Why It Matters Now
Here’s something that surprises a lot of people. Generative AI exploded onto the scene and delivered incredible creative output, but many companies reported little to no bottom-line impact. Why? Because it still needed humans to steer every step, review every draft, and connect the dots.
Agentic AI flips the script. It’s proactive rather than reactive. You give it a goal, like “optimize our quarterly marketing spend across channels,” and it doesn’t just draft a report. It pulls live data from analytics platforms, runs simulations, flags underperforming campaigns, reallocates budget in real time, and even drafts the stakeholder update. All while staying within your approved policies.
The transition isn’t overnight, of course. We’re still in the messy middle. But 2026 marks a clear inflection point. Multi-agent orchestration, where specialized agents team up like a digital squad, is becoming the enterprise standard. Single agents handle narrow jobs; swarms tackle end-to-end workflows.
Honestly, this isn’t talked about enough: the real value isn’t in replacing people but in freeing them for higher-order thinking. Generative tools augmented creativity. Agentic systems are augmenting execution.
How Autonomous Agents Really Work
You might be wondering what actually happens under the hood. It boils down to a few interlocking pieces that create that magic “think-act-observe” cycle.
First comes reasoning and planning. Agents use techniques like ReAct (reason plus act) to break big goals into logical steps. They don’t guess blindly; they evaluate options, predict outcomes, and sequence tasks. Some even employ multi-step reasoning that looks a lot like how you or I tackle a tough project: research, draft, test, refine.
Tool use is the real differentiator. Unlike pure language models stuck inside their training data, agents can reach out. Need current stock prices? Call an API. Need to scrape competitor sites? Fire up the browser tool. Need to update a CRM record? Integrate directly. This tool-calling capability turns static intelligence into dynamic action.
Memory matters too. Short-term memory keeps track of the current conversation or workflow. Long-term memory stores lessons from past runs so the agent gets smarter over time. And in multi-agent setups, agents share context, hand off subtasks, and even debate solutions before converging on the best path.
The loop repeats: plan, act, observe feedback, replan if necessary. It’s iterative, resilient, and surprisingly human-like in its adaptability.
Real-World Examples Making Waves in 2026
Theory is fine, but let’s talk results. Companies aren’t waiting around.
In customer support, agents now handle entire ticket lifecycles. One system might classify an issue, pull customer history, check inventory or billing systems, propose solutions, and follow up if the customer doesn’t respond, all without escalating to a human until truly needed.
Finance teams use them for fraud detection that evolves in real time. JPMorgan-style platforms scan millions of transactions, spot anomalies, and trigger holds or investigations autonomously. No more rigid rule sets that break the moment patterns shift.
Supply chain and logistics? Agents reroute shipments, negotiate with carriers via APIs, and adjust production schedules based on live demand signals. One prediction I love: by the end of this year, end-to-end logistics will run on orchestrated agent teams in many large manufacturers.
Even creative fields are seeing the shift. Research synthesis agents comb through papers, patents, and market data to produce executive briefings that would have taken weeks manually. DevOps teams deploy auto-remediation agents that detect outages, diagnose root causes, and roll out fixes while paging the on-call engineer only as a last resort.
These aren’t pilots anymore. They’re in production, delivering measurable ROI.
Popular Frameworks Powering Agentic Systems
Building these agents from scratch sounds intimidating, but frameworks have matured fast. Here are a few standouts you’ll hear about constantly in 2026:
- LangGraph shines for stateful, controllable workflows. It lets developers visualize and debug those reasoning loops like a flowchart come to life.
- CrewAI feels like the team-builder. You assign roles to specialized agents (researcher, writer, critic) and watch them collaborate on complex projects.
- AutoGen from Microsoft excels at multi-agent conversations, perfect when you need agents to negotiate or divide labor dynamically.
Other options like LlamaIndex handle data-heavy retrieval, while Semantic Kernel integrates neatly into Microsoft’s ecosystem. The beauty is you don’t need a PhD to get started; many now offer low-code interfaces for non-technical users.
Pros and Cons: A Balanced Look
No technology is perfect, so let’s lay it out plainly.
| Aspect | Pros | Cons |
|---|---|---|
| Efficiency | Handles multi-step workflows 24/7 | Can rack up API costs quickly |
| Scalability | Orchestrates hundreds of agents easily | Requires robust governance to avoid chaos |
| Adaptability | Learns from outcomes and self-corrects | Still prone to edge-case hallucinations |
| Human Focus | Frees people for strategy and creativity | Raises questions around accountability |
| Integration | Connects seamlessly with existing tools | Data quality issues can derail everything |
On balance, the upsides win for most organizations willing to invest in guardrails. But ignore the downsides at your peril.
Challenges You’ll Face (and How to Tackle Them)
You might not know this, but data readiness trips up more initiatives than anything else. Agents starve without clean, structured information. Start with intelligent document processing to unlock trapped data in PDFs and emails.
Governance is another hot topic. Who’s responsible when an agent makes a costly mistake? Smart teams build in audit trails, approval gates for high-stakes actions, and “human-in-the-loop” escalation paths.
Security and compliance can’t be afterthoughts either, especially in regulated industries. Role-based permissions, encrypted tool calls, and regular red-teaming keep things safe.
Cost management? Monitor usage religiously. Many organizations begin with narrow, high-ROI use cases before scaling to full agent swarms.
FAQ
What’s the main difference between generative AI and Agentic AI?
Generative AI creates content in response to prompts. Agentic AI goes further: it pursues goals by planning, acting, and adapting until the job is done. One generates; the other executes.
Do I need coding skills to build Agentic AI agents?
Not necessarily. While frameworks like LangGraph offer powerful customization for developers, many platforms now provide visual builders and no-code options that let business users assemble agents quickly.
Are Agentic AI systems safe for enterprise use?
They can be, provided you implement proper guardrails, monitoring, and governance. Most production deployments include human oversight for critical decisions and detailed logging for accountability.
How much does Agentic AI cost to implement?
It varies wildly. Simple agents might run on a few dollars a day in API fees, while enterprise multi-agent systems require infrastructure investment. Focus on high-ROI workflows first to prove value quickly.
Will Agentic AI replace human jobs?
It’s more accurate to say it will transform them. Routine, multi-step tasks move to agents, letting people focus on judgment, creativity, and relationship-building. The winners will be those who learn to collaborate with agents effectively.
What’s the best starting point for a small business?
Pick one painful, repetitive process that spans a few tools (like lead qualification or invoice chasing). Prototype a single agent, measure results, then expand.
Can Agentic AI work offline or with sensitive data?
Yes, through on-premise or private-cloud deployments and secure tool integrations. Several frameworks support air-gapped environments for highly regulated sectors.
Final Thoughts: Where Agentic AI Heads Next
Here’s my take after watching this space evolve: Agentic AI isn’t a flashy gadget; it’s infrastructure, like electricity or the internet before it. By late 2026, we’ll look back and wonder how we ever managed without autonomous digital teammates handling the grunt work.
Some experts disagree on timelines, but the momentum feels unstoppable. Multi-agent ecosystems will get smarter, physical agents will bridge digital and real-world actions, and governance standards will catch up.
The question isn’t whether Agentic AI will change your world. It’s whether you’ll be the one directing the agents or scrambling to catch up. Start small, stay curious, and experiment boldly. The future belongs to those who treat these systems as collaborators, not just tools.
What’s one workflow in your day-to-day that you’d love to hand off to an autonomous agent? Drop it in the comments. I’d love to hear where you see the biggest opportunity.
You may also like: Best AI Image Editor with Prompt-Free Features of 2025
-

 Education2 years ago
Education2 years agoMastering Excel: Your Comprehensive Guide To Spreadsheets And Data Analysis
-

 Tech2 years ago
Tech2 years agoHow To Choose The Best Forex Trading Broker?
-

 Business2 years ago
Business2 years agoExploring the Rental Market: Properties for Rent in Malta
-

 Blog2 years ago
Blog2 years agoArab MMA Fighters Shine Bright: Meet the Champions of PFL MENA
-

 Travel2 years ago
Travel2 years agoExperience the Best Desert Safari Dubai Offers!
-

 Home Improvement2 years ago
Home Improvement2 years agoEco-Friendly Round Rug Options for Sustainable Living in NZ
-

 Tech2 years ago
Tech2 years agoThe Role Of Experts VS Top Mobile Apps for Green Screen Removal
-

 How-To Guides2 years ago
How-To Guides2 years agoComprehensive Guide to Cockwarming: Enhancing Intimacy and Connection